Dockerize Airflow
Airflow is the de facto ETL orchestration tool in most data engineers tool box. It provides an intuitive web interface for a powerful backend to schedule and manage dependencies for your ETL workflows.
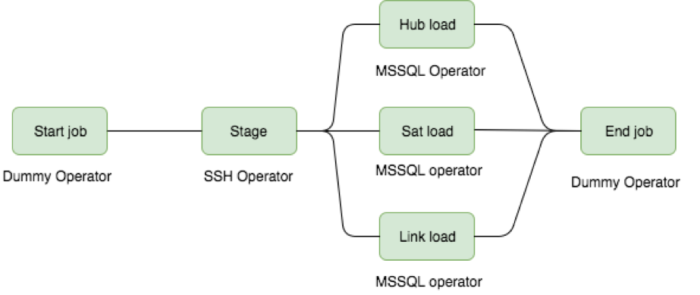
In my day to day work-flow, I use it to maintain and curate a data lake built on top of AWS S3. Nodes in my Airflow DAGs include multi-node EMR Apache Spark and Fargate clusters that aggregate, prune and produce para-data from a data lake.
These work-flows are executed on distributed clusters (20+ nodes) and have heavy inter-dependencies (i.e. output from one ETL is fed in as input to the next), this is why it made sense to orchestrate them using Airflow. However it did not make sense to have a centralized Airflow deployment as I will be the only one using it.
I therefore chose to Dockerize Airflow so that I could spin up a container and easily run these work-flows without having to worry about the Airflow deployment.
In this Medium post I go over how I achieved this along with some brief explanation of design decisions along the way.